近期实验室新购买一台服务器,配备了全新的3块RTX3090显卡。由于需要安装全新的显卡驱动以及CUDA,cuDNN才能正常使用。
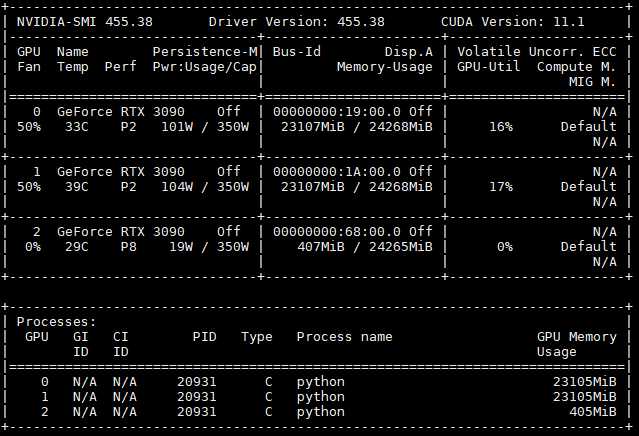
使用watch -n 1 nvidia-smi可以时时实时查看所有显卡的使用情况,并且可以查看驱动版本以及需要的CUDA版本,如下所示:驱动版本是455.38,需要的CUDA为11.1版本(这是我已经安装好了驱动的情况下显示的),如果你的驱动版本过低或者没有安装驱动,那么请参考其他的文章进行安装。
另外,建议使用Anaconda进行环境管理,不容导致整体包环境错乱。
目录
安装Tensorflow与Python
后面介绍的TensorRT仅支持Python 3.7,所以请使用Anaconda或其他方式安装python 3.7,
新版的RTX3090更方便在Tensorflow 2.4.0使用,所以请使用
pip install tensorflow==2.4.0
进行2.4.0版本的安装,2.3.0版本会出现各种错误。
安装CUDA 11.1
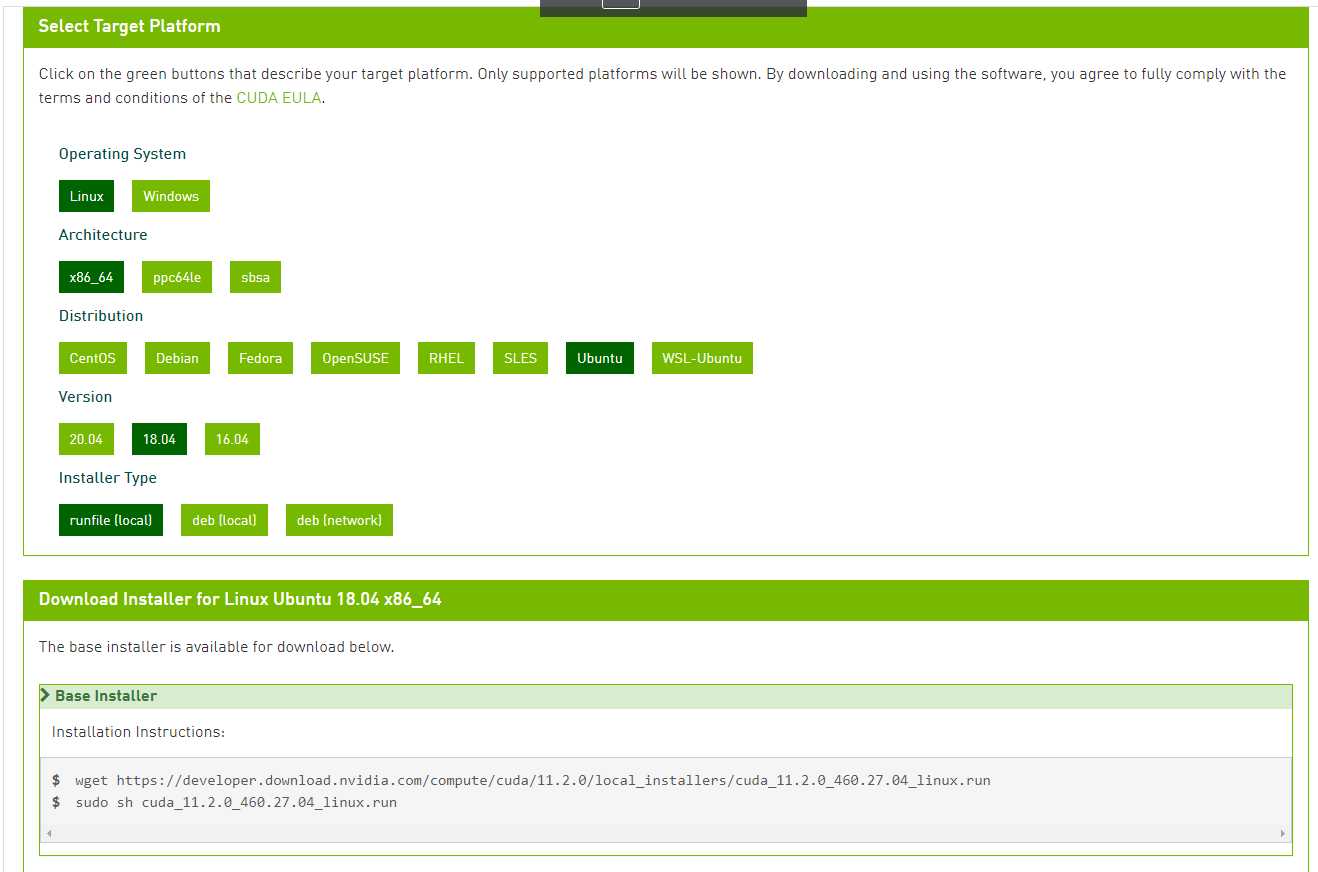
首先打开下载地址:https://developer.nvidia.com/cuda-toolkit-archive 找到最新发布的CUDA,我下载的是11.2.0:

之后依次选择linux->x86_64->Ubuntu 18.04,安装类型选runfile(local)这一系列配置:
采用wget方式下载会比较慢,建议采用迅雷下载到本地再上传服务器,或者其他方式下载。下载好之后,使用
sudo sh cuda_11.1.1_455.32.00_linux.run
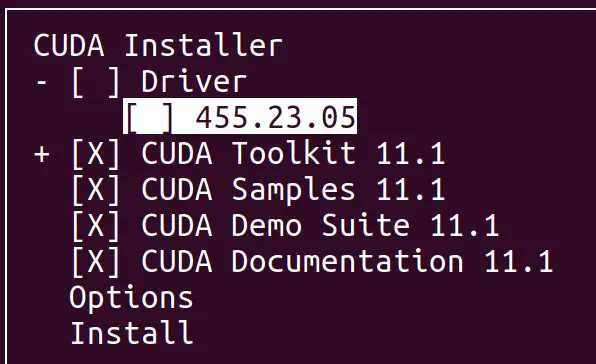
运行,如果不能运行,试一下chmod -R 777 cuda_11.1.1_455.32.00_linux.run提权。使用sh脚本安装的过程中会提示已安装驱动,选择continue即可,然后accept。注意在安装时,因为我已经有显卡驱动,所以需要把Driver那个选项按空格键取消,然后选Install安装。
安装完之后配置环境变量:
sudo vim ~/.bashrc
没有vim的自行安装(sudo apt install vim),或使用vi。
在~、.bashrc末尾添加:
export CUDA_HOME=/usr/local/cuda
export LD_LIBRARY_PATH={LD_LIBRARY_PATH}:{CUDA_HOME}/lib64
export PATH={CUDA_HOME}/bin:{PATH}
保存之后source ~/.bashrc激活环境变量,如果退出了你自定义的anaconda环境记得重新activate进去。
最后输入nvcc -V验证CUDA是否已安装,并返回版本号等信息。输出信息如下:
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2020 NVIDIA Corporation
Built on Mon_Oct_12_20:09:46_PDT_2020
Cuda compilation tools, release 11.1, V11.1.105
Build cuda_11.1.TC455_06.29190527_0
配置对应的cuDNN
首先打开下载地址:https://developer.nvidia.com/rdp/cudnn-download
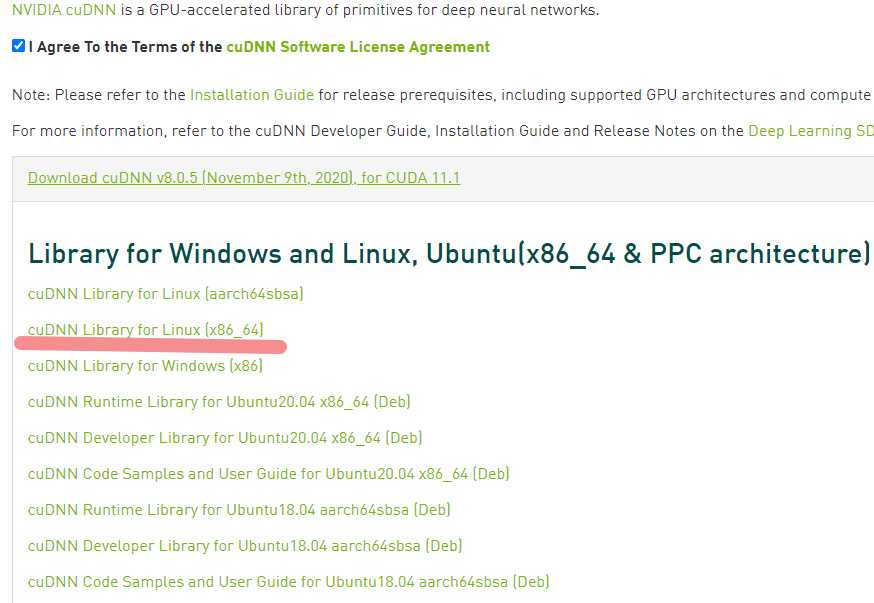
这里需要登陆或注册Nvidia账号,如果是第一次下载,可能还要填一份调查问卷,然后根据提示选择版本,这里选的是cuDNN Library for Linux (x86_64)
建议采用迅雷下载到本地再上传服务器,或者其他方式下载。下载下来的是cudnn-11.1-linux-x64-v8.0.5.39.solitairetheme8文件,上传到服务器之后,可以使用:
cp cudnn-11.1-linux-x64-v8.0.5.39.solitairetheme8 cudnn-11.1-linux-x64-v8.0.5.39.tgz
转为tgz的压缩文件,随后进行加压:
tar -zxvf cudnn-11.1-linux-x64-v8.0.5.39.tgz
接下来把cudnn的文件复制到CUDA目录:
sudo cp cuda/lib64/* /usr/local/cuda/lib64/
sudo cp cuda/include/* /usr/local/cuda/include/
sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
最后验证cudnn是否配置好并输出版本号:
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
输出如下:
#define CUDNN_MAJOR 8
#define CUDNN_MINOR 0
#define CUDNN_PATCHLEVEL 5
--
#define CUDNN_VERSION (CUDNN_MAJOR * 1000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL)
#endif /* CUDNN_VERSION_H */
配置TensoRT
打开下载地址:https://developer.nvidia.com/tensorrt
登陆Nvidia账号,同样的可能会让填一份问卷,提交之后点击立即下载。这里选择版本为"TensorRT 7.2.1 for Ubuntu 18.04 and CUDA 11.1 TAR package"
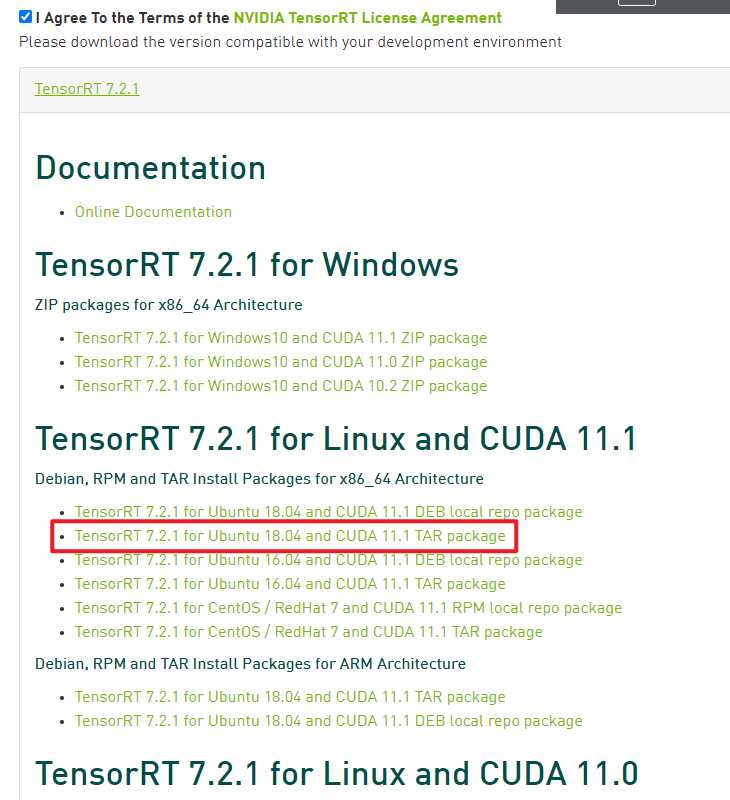
同样把它下载,然后解压并配置:
tar -zxvf TensorRT-7.2.1.6.Ubuntu-18.04.x86_64-gnu.cuda-11.1.cudnn8.0.tar.gz
sudo mv TensorRT-7.2.1.6 /usr/local/TensorRT-7.2.1.6
sudo ln -s /usr/local/TensorRT-7.2.1.6 /usr/local/tensorrt
然后配置环境变量,打开:
sudo vim ~/.bashrc
在文件末尾添加:
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/local/tensorrt/lib
然后更新环境变量:
source ~/.bashrc
最后一步
以上步骤安装完之后,可以采用以下代码进行测试
import tensorflow as tf
import timeit
with tf.device('/gpu:0'):
cpu_a = tf.random.normal([10000, 1000])
cpu_b = tf.random.normal([1000, 2000])
print(cpu_a.device, cpu_b.device)
with tf.device('/gpu:1'):
gpu_a = tf.random.normal([10000, 1000])
gpu_b = tf.random.normal([1000, 2000])
print(gpu_a.device, gpu_b.device)
def cpu_run():
with tf.device('/gpu:0'):
c = tf.matmul(cpu_a, cpu_b)
return c
def gpu_run():
with tf.device('/gpu:1'):
c = tf.matmul(gpu_a, gpu_b)
return c
# warm up
for i in range(1000):
cpu_time = timeit.timeit(cpu_run, number=10)
gpu_time = timeit.timeit(gpu_run, number=10)
print('warmup:', cpu_time, gpu_time)
cpu_time = timeit.timeit(cpu_run, number=10)
gpu_time = timeit.timeit(gpu_run, number=10)
print('run time:', cpu_time, gpu_time)
print(f'Count {i}/10000')
如果出现以下错误
Could not load dynamic library 'libcusolver.so.10'; dlerror: lipen shared object file: No such file or directory; LD_LIBRARY_PATH: :/usr/local/cuda/lib64:/usr/local/tensorrt/lib
那么可以采用以下解决办法
sudo ln -s /usr/local/cuda-11.1/targets/x86_64-linux/lib/libcusolver.so.11 /usr/loc64-linux/lib/libcusolver.so.10
