最近参加了鹅厂的实习面试,总结一下问题和答案如下:
最近的鹅厂的一面经历如下:
- 1)自我介绍
这个环节是每个公司每一轮面试都会有的,一般是三五分钟,突出自己的重点和亮点就行。
- 1.1)问了问是什么类型的硕士,以及什么时间可以去实习
- 1.2)问了在本科和研究生阶段做过的认为最大项目(这一关如果卡住的话非常的尴尬)
- 2)问了熟悉的语言,然后开始做题:
- 2.1) 第一题:
输入一个日志文件(sysbench log)、每一秒动态更新,编写函数,当有连续3条日志tps值小于整个tps均值80%打印err信息
[ 1s ] thds: 512 tps: 5723.51 qps: 36159.53 (r/w/o: 0.00/24208.98/11950.55) lat (ms,95%): 253.35 err/s: 0.00 reconn/s: 0.00
[ 2s ] thds: 512 tps: 5263.41 qps: 31171.41 (r/w/o: 0.00/20646.60/10524.81) lat (ms,95%): 314.45 err/s: 0.00 reconn/s: 0.00
[ 3s ] thds: 512 tps: 5769.74 qps: 35377.39 (r/w/o: 0.00/23842.91/11534.47) lat (ms,95%): 189.93 err/s: 0.00 reconn/s: 0.00
[ 4s ] thds: 512 tps: 7850.52 qps: 47059.14 (r/w/o: 0.00/31346.09/15713.05) lat (ms,95%): 112.67 err/s: 0.00 reconn/s: 0.00
考察的知识点:
- a)动态更新文件的读取
- b)字符串的提取
- c)seek以及tell方法的使用

- 2.2)第二题

考察的知识点:
- a) json数据格式的转换,使用json.loads()进行解码
- b) 多子节点树的遍历
- c)深拷贝和浅拷贝的细节
- d)实现的过程涉及到回溯的思想
代码如下:
import json
def solution(json_str: str):
path,ans=[],[]
json_dict = json.loads(json_str)
dfs(json_dict, path=path, ans=ans)
return ans
def dfs(root, path, ans):
if 'data' not in root:
path.append(root['node'])
ans.append(path.copy()) # 如果不加copy(),那么后续的path操作会影响ans里面已经加入的path,属于浅拷贝和深拷贝的知识点
print('路径为 ',path)
return
path.append(root['node'])
for nd in root['data']:
dfs(nd, path, ans)
if path:
print('弹出的元素为 ', path.pop(), '弹出之后的路径为 ', path)
json_str="""
{
"node": "A",
"data": [{
"node": "B1",
"data": [{
"node": "C1"
}]
},
{
"node": "B2",
"data": [{
"node": "C2",
"data": [{
"node": "D1"
}]
}]
},
{
"node": "B3"
}
]
}
"""
json_str=json_str.replace('\n','').replace('\t','')
ans=solution(json_str)
- 2.3第三题:
sql
t1(name,subject,score,grade)是一张表,存储了学生的姓名,科目名称,以及各科分数和班级。使用SQL语句实现3班学生成绩单排名,输出姓名、各科总分,降序排序- 问答环节
- 1)实存和虚存的区别
#### 什么是虚存?什么是实存?
在操作系统当中,CPU以及主内存(物理内存)都是十分稀缺的资源,正在运行的进程可以对CPU以及物理内存资源进行访问。为了更好以及更加高效的运用物理内存,引入了虚拟内存的概念。
虚拟内存可以理解为进程和物理内存的中间层,为进程提供了统一和方便的访问内存接口。

如下图所示,现代操作系统中,进程持有的都是虚拟内存的地址,通过内存管理单元(Memory Management Unit)来实现虚拟内存地址到物理内存地址的映射,进而访问数据。
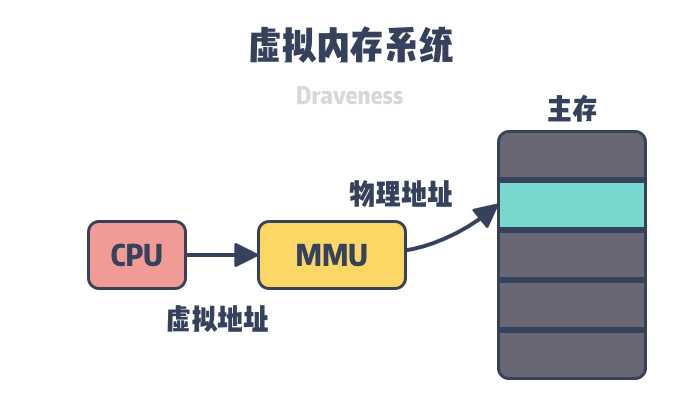
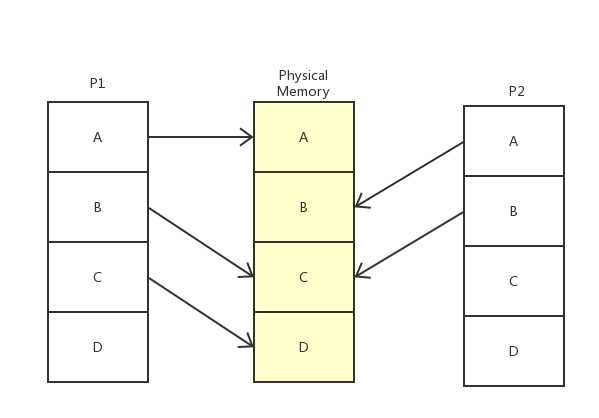
使用了虚拟内存之后,对于每一个进程而言,操作系统告诉进程的是他们可以对整个内存空间进行操作,而这实际上只是虚拟内存“耍的小聪明”。如P1,P2进程所见的是可以直接占用整个内存(A,B,C,D),但实际上甚至存在C内存块资源共享的情况。这体现了使用虚拟内存的另一个优点,对进程而言,虚拟内存为进程提供了独立连续的内存空间,使得进程之间互不干扰。
更为重要的是由于进程访问内存时,都要通过页表来寻址,操作系统在页表的各个项目上添加各种访问权限标识位,就可以实现内存的权限控制。 - 2)说说你经常使用的Linux指令
这个问题主要是考察对Linux的熟悉程度,但是回答的时候需要有逻辑性。不要想到什么说什么,可以分门别类进行描述。- a)最简单的关机重启指令:
- shutdown[-k: 不会关机,但是会通知所有的用户 -r 将系统的所有服务停止之后就关机 -h 过了多少分钟之后关机(now 表示现在关机) -c 取消正在运行的shutdown命令]
- halt 直接关机指令
- reboot 重启机器
- b) 添加用户,切换用户登录与注销
useradd [-g 添加用户时制定用户组 -d 指定用户的home目录].(推荐使用adduser,相当的方便)- su [- username 切换登录用户]
- logout 退出当前登录的用户
- userdel [-r 使用-r保存用户的home目录]
- groupdel/groupadd [删除/添加用户组]
- c) 文件操作指令
- pwd 显示当前路径
- ls [-a 列出当前路径下的所有文件和目录,包括隐藏文件 -l 以列表的方式暂时 -h 显示文件的大小]
- cd 切换目录
- mkdir 创建文件夹
- rmdir 删除空文件夹(文件夹当中有文件时候使用rm -rf进行删除)
- touch 创建空文件
- cp source dest 移动文件
- rm [-r 递归删除文件 -f 强制删除不提醒]
- mv oldName NewName文件重命名,mv fileName /otherFile 移动文件
- cat [-n 显示多少行号,如果不使用,那么从开头往后已知打印出来]
- tac 从最后一行开始往前打印
- more 以分页模式进行打印输出,更加的人性化
- less 与more的作用的类似
- head [-n 打印查看前多少行的数据]
- tail [-n 打印查看文件尾部多少行数据]
- ln 创建文件的软连接(可以理解为快捷方式)
- cut 对文件进行切分
- c) 搜索查找指令
- find [-name 查找指定的文件名(支持正则匹配) -size 查找符合要求的指定范围内的文件大小的文件]
- grep 查找文件当中符合要求的字符串 [-n 显示匹配内容及其行号 -c 统计匹配到行的个数 -i 忽略大小写 -v 反向选择,显示没有被匹配的字符换]
管道符号 | 表示将前一个命令的处理结果交给后一个命令处理
- d) 压缩解压
- gzip/gunzip 将文件压缩/解压为.gz的压缩文件
- zip/unzip 将文件压缩/解压为.zip文件
- e)进程管理
- ps [-a 显示当前终端所有的进程 -u 以用户格式显示进程 -x显示后台运行参数 -e 显示所有进程 -f 全格式]
- ps -aux 以用户格式显示当前终端的所有进程参数信息
- ps -aux | grep xxx 找出符合条件的进程
- ps -l 查看自己所有的进程
- top 以动态更新的方式查看进程信息
- a)最简单的关机重启指令:
- 3) 说说你所了解的几种设计模式
- a) 单例模式(singleton):如果一个类始终只能创建一个实例,则这个类被称为单例类,这种模式就被称为单例模式。该设计模式的优点是:减少创建实例所带来的系统开销,便于系统跟踪单个实例的生命周期、实例状态等。
- b) 装饰者模式( Decorator ):动态的给一个对象添加一些额外的功能。Python中体现为装饰器对象或者装饰器函数。
- c) 工厂模式(Factor):定义一个用于创建对象的接口函数Interface,让子类决定实例化哪一个类。
class ClassA:
def __init__(self):
print('Init with class A')
class ClassB:
def __init__(self):
print('Init with class B')
class FactorInterface:
def __init__(self, init_class):
self.init_class=init_class
def init(self): #定义一个创建对象的接口,但是交给子类来决定实现什么
return self.init_class()
class_a=FactorInterface(ClassA).init() #工厂模式交由之类来决定具体实例化哪一种类
class_b=FactorInterface(ClassB).init()
- 1) 简单工厂模式:相比于工厂模式而言,其中包括含大量的判断语句,会依据传入工厂函数的参数实例化具体的类。严格来说,这并不属于设计模式,可以算作编码习惯。
- 2) 抽象工厂模式:供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。这种模式有点类似于多个供应商负责提供一系列类型的产品。不但工厂是抽象的,产品也是抽象的。抽象工厂模式通常一组工厂方法。抽象工厂模式与工厂方法模式最大的区别:抽象工厂中每个工厂可以创建多种类的产品;而工厂方法每个工厂只能创建一类。抽象工厂模式的实现步骤:
- 步骤1: 创建抽象工厂类,定义具体工厂的公共接口;
- 步骤2: 创建抽象产品族类 ,定义抽象产品的公共接口;
- 步骤3: 创建抽象产品类 (继承抽象产品族类),定义具体产品的公共接口;
- 步骤4: 创建具体产品类(继承抽象产品类) & 定义生产的具体产品;
- 步骤5:创建具体工厂类(继承抽象工厂类),定义创建对应具体产品实例的方法;
- 步骤6:**客户端通过实例化具体的工厂类,并调用其创建不同目标产品的方法创建不同具体产品类的实例**
- 适配器模式:目的是为了是两个不兼容的类或者接口相互兼容。
#target, 需要安卓的充电县
class Android:
def __init__(self):
pass
def connect_mobile(self,mobile):
print('我是安卓手机,需要安卓手机充电线')
mobile.connectAn()
#adapter
class Adapter:
def __init__(self):
self._connectApple=Apple()
def connectAn(self):
print('适配器来了,是个转换接口,苹果充电线接上适配器就能给安卓手机充电了')
self._connectApple.connectAp()
#adaptee , 这是个苹果手机的充电线
class Apple:
def __init__(self):
pass
def connectAp(self):
print('有苹果手机充电线')
if __name__=='__main__':
androidM=Android()
adapter=Adapter()
androidM.connect_mobile(adapter)
4)为什么TCP不能三次挥手
- TCP的工作方式是典型的双工方式,客户端和服务器端都必须接收到对方的FIN信号才能结束和对方的通信。如果仅有三次挥手:第一次挥手客户端发送FIN给服务端,第二次挥手服务端收到之后回复ACK信号,此时代表由客户端到服务端的通信结束。第三次挥手为服务器端向客户端发送FIN信号,如果没有最后客户端回复ACK信号,那么服务器端的FIN信号是否达到客户端不得而知,也就不能关闭从服务端到客户端的连接。
5)说一说死锁的形成以及如何消除
- 死锁的形成:死锁的形成是由于两个或以上的进程对资源的抢占所导致的,死锁的发生需要以下四个必备条件:
- 互斥条件:进程所抢占到的资源不允许其他进程访问,若其他进程想访问只能等待(例如对文件的写),直到占有该资源的进程使用完成之后释放该资源。
- 请求与保持条件:进程获得一定的资源之后,又对其他的资源发出请求,但是不释放已有的资源,此时请求阻塞。
- 不可剥夺条件:进程抢占到的资源在没有使用完之前是不可被剥夺的,只能自己使用完之后自己释放。
- 环路等待条件:若干进程形成首尾相接的循环等待资源的关系
- 解决死锁的方法:可以通过消除以上四个形成条件来解决
- 针对互斥条件:可以使得资源变为同时访问而非互斥访问(如读文件资源),但是这种方式在很多条件下不适用。
- 针对请求与保持条件:对进程采用静态资源分配方式,只有所有的资源申请得到所有需要的资源才能开始进程(实现简单,但是极大地降低了资源利用率)。
- 针对不可剥夺条件:占有资源的进程如果需要申请新的资源就强制释放已有的资源
- 针对环路等待条件:使用资源有序分配法,给系统所有的可申请资源编号。每个进程申请资源按照序号递增申请。
