目录
窗口函数概述
窗口函数(Window Function)针对查询中的每一行数据,基于和它相关的一组数据计算出一个结果。顾名思义,每一行都会对应一个计算结果,而不是将一组结果聚合计算成一条结果,原始数据有多少行,窗口函数计算之后还是有多少行。
创建数据
CREATE TABLE sales
(
year INT,
country VARCHAR(20),
product VARCHAR(32),
profit INT
);
insert into sales(year, country, product, profit)
values
(2000, 'Finland', 'Computer', 1500),
(2001, 'USA', 'Computer', 1200),
(2001, 'Finland', 'Phone', 10),
(2000, 'India', 'Calculator', 75),
(2001, 'USA', 'TV', 150),
(2000, 'India', 'Computer', 1200),
(2000, 'USA', 'Calculator', 75),
(2000, 'USA', 'Computer', 1500),
(2000, 'Finland', 'Phone', 100),
(2001, 'USA', 'Calculator', 50),
(2001, 'USA', 'Computer', 1500),
(2000, 'India', 'Calculator', 75),
(2001, 'USA', 'TV', 100);
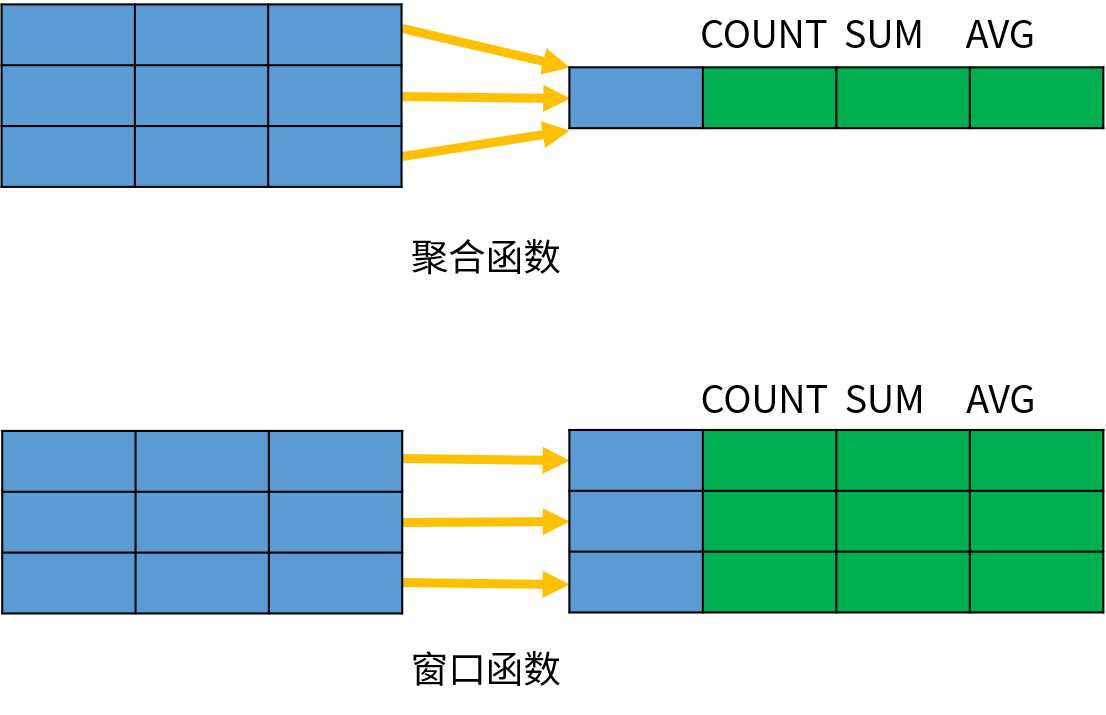
聚合函数和窗口函数的区别:
mysql> SELECT SUM(profit) AS total_profit FROM sales;
+--------------+
| total_profit |
+--------------+
| 7535 |
+--------------+
1 row in set (0.00 sec)
SELECT year, country, product, profit,
SUM(profit) OVER() AS total_profit
FROM sales;
mysql> SELECT year, country, product, profit,
-> SUM(profit) OVER() AS total_profit
-> FROM sales;
+------+---------+------------+--------+--------------+
| year | country | product | profit | total_profit |
+------+---------+------------+--------+--------------+
| 2000 | Finland | Computer | 1500 | 7535 |
| 2001 | USA | Computer | 1200 | 7535 |
| 2001 | Finland | Phone | 10 | 7535 |
| 2000 | India | Calculator | 75 | 7535 |
| 2001 | USA | TV | 150 | 7535 |
| 2000 | India | Computer | 1200 | 7535 |
| 2000 | USA | Calculator | 75 | 7535 |
| 2000 | USA | Computer | 1500 | 7535 |
| 2000 | Finland | Phone | 100 | 7535 |
| 2001 | USA | Calculator | 50 | 7535 |
| 2001 | USA | Computer | 1500 | 7535 |
| 2000 | India | Calculator | 75 | 7535 |
| 2001 | USA | TV | 100 | 7535 |
+------+---------+------------+--------+--------------+
13 rows in set (0.00 sec)
由此验证了之前的说法,窗口函数不会减少数据的行数。
窗口函数的基本语法
window_function(expr)
OVER (
PARTITION BY ...
ORDER BY ...
frame_clause
)
PARTITION BY
OVER 子句包含三个可选项:分区(PARTITION BY)、排序(ORDER BY)以及窗口大小(frame_clause)。PARTITION BY 选项用于将数据行拆分成多个分区(组),窗口函数基于每一行数据所在的组进行计算并返回结果。如果省略了 PARTITION BY,所有的数据作为一个组进行计算。在上面的示例中,SUM(profit) OVER() 就是将所有的销售数据看作一个分区。以下为按照国家对利润进行求和,同时每个国家内的每一条数据显示的利润和是相同的。
mysql> SELECT year, country, product, profit,
-> SUM(profit) OVER(PARTITION BY country) AS country_profit
-> FROM sales;
+------+---------+------------+--------+----------------+
| year | country | product | profit | country_profit |
+------+---------+------------+--------+----------------+
| 2000 | Finland | Computer | 1500 | 1610 |
| 2001 | Finland | Phone | 10 | 1610 |
| 2000 | Finland | Phone | 100 | 1610 |
| 2000 | India | Calculator | 75 | 1350 |
| 2000 | India | Computer | 1200 | 1350 |
| 2000 | India | Calculator | 75 | 1350 |
| 2001 | USA | Computer | 1200 | 4575 |
| 2001 | USA | TV | 150 | 4575 |
| 2000 | USA | Calculator | 75 | 4575 |
| 2000 | USA | Computer | 1500 | 4575 |
| 2001 | USA | Calculator | 50 | 4575 |
| 2001 | USA | Computer | 1500 | 4575 |
| 2001 | USA | TV | 100 | 4575 |
+------+---------+------------+--------+----------------+
13 rows in set (0.00 sec)
ORDER BY
ORDER BY 选项用于指定分区内数据的排序,排序字段数据相同的行是对等行(peer)。如果省略 ORDER BY ,分区内的数据不进行排序,不按照固定顺序处理, 而且所有数据都是对等行。以下查询按照国家进行分组,按照年份和产品名称进行排序,然后汇总销量:
mysql> SELECT year, country, product, profit,
-> SUM(profit) OVER(PARTITION BY country ORDER BY year, product) AS country_profit
-> FROM sales;
+------+---------+------------+--------+----------------+
| year | country | product | profit | country_profit |
+------+---------+------------+--------+----------------+
| 2000 | Finland | Computer | 1500 | 1500 |
| 2000 | Finland | Phone | 100 | 1600 |
| 2001 | Finland | Phone | 10 | 1610 |
| 2000 | India | Calculator | 75 | 150 |
| 2000 | India | Calculator | 75 | 150 |
| 2000 | India | Computer | 1200 | 1350 |
| 2000 | USA | Calculator | 75 | 75 |
| 2000 | USA | Computer | 1500 | 1575 |
| 2001 | USA | Calculator | 50 | 1625 |
| 2001 | USA | Computer | 1200 | 4325 |
| 2001 | USA | Computer | 1500 | 4325 |
| 2001 | USA | TV | 150 | 4575 |
| 2001 | USA | TV | 100 | 4575 |
+------+---------+------------+--------+----------------+
13 rows in set (0.00 sec)
ORDER BY 之后的表达式也可以使用 ASC 或者 DESC 指定排序方式,默认为 ASC。对应升序排序,NULL 排在最前面;对于降序排序,NULL 排在最后面.OVER 子句中的 ORDER BY 选项只用于分区内的数据排序;如果想要对最终的结果进行排序,可以使用 ORDER BY 子句。
窗口选项
frame_clause 选项用于在当前分区中指定一个数据窗口,也就是一个与当前行相关的数据子集。窗口会随着当前处理的数据行而移动,例如:
- 定义一个从分区开始到当前数据行结束的窗口,可以计算截止到每一行的累计总值。
- 定义一个从当前行之前 N 行数据到当前行之后 N 行数据的窗口,可以计算移动平均值。
{ROWS | RANGE} frame_start
{ROWS | RANGE} BETWEEN frame_start AND frame_end
其中,ROWS表示偏移的行数。frame_start表示窗口的起始位置,常见的有三种选项:
- UNBOUNDED PRECEDING,为默认值,表示从第一行开始。
- N PRECEDING,表示从前N行开始,如果数据缺失则为0 。
- CURRENT ROW,表示从当前行开始。
frame_end表示窗口的结束位置,有三种选项:
- CURRENT ROW为默认值,表示从当前行结束。
- N FOLLOWING,表示当前行后的第N行结束。
- UNBOUNDED FOLLOWING,表示窗口到分区的最后一行结束。
如果使用的RANGE选项,那么具有同样的排序值的所有行会被当成一行来对待。
