目录
epoll
如果说epoll和select/poll在什么地方具有相同点,那么他们的共同点在于epoll也是需要将监听的文件描述符纳入自己的"监管"。但是select和poll存在自己的一些“天生”的缺点,比如都需要不断地在用户空间和内核空间进行反复的拷贝传递,以及它们在轮询查找可读可写事件的时间复杂度都是线性时间复杂度(表现在select/poll返回值包括了就绪的事件和未就绪的事件,而之后是需要我们自己去判断哪一个文件描述符是就绪了的)。但是,一旦并发量上来了(到达10W和100W级别),如果还是线性的轮询时间复杂度,那么效率是十分的低下。因此,epoll的底层实现机制和select/poll存在本质上的不一样。
epoll把用户关心的文件描述符放在内核的事件表当中,使用一组函数来完成任务,而不需要向select/poll那样每次调用都需要重复传入文件描述符集或者事件集,这里所说的内核事件表可以认为是一个内核中特殊的文件,实际上它也确实是一个文件,在之后的创建事件表的时候,返回值也确实是文件描述符。真是由于这个事件表存在于内核中,因此可以直接通过文件描述符找到它,不需要反复在用户空间和内核空间之间进行传递。但是缺点也在于需要占用一个额外的文件描述符。
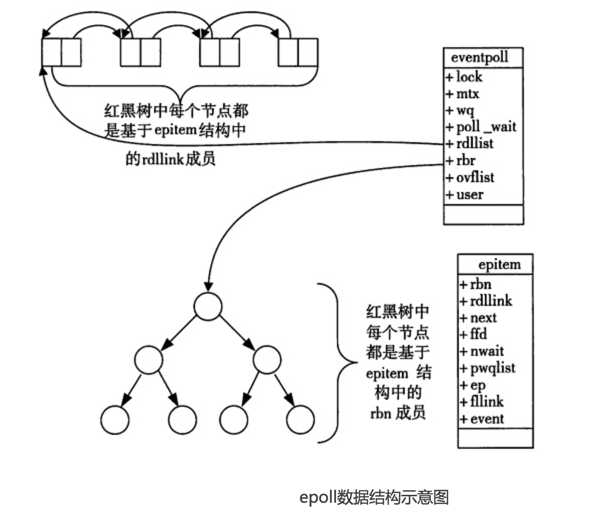
epoll实现只要使用的数据结构有红黑树,双向链表两种。内核事件表就是基于红黑树实现的,红黑树对于插入和删除操作的时间复杂度是O(logN),避免了线性表的O(N)时间复杂度。双向链表是存储就绪事件的数据结构。
题外话:为什么epoll是使用红黑树我不是时间复杂度O(1)的hashtable呢?有一个未经验证的说法就是,因为当时内核里有现成的rbtree而没有通用的hashtable数据结构。另外一种说法是,使用hashtable需要经常rehash会造成大量的空闲空间,属于空间换时间。使用双向链表同样是为了插入和删除就绪时间更加方便。
epoll工作流程
epoll主要的工作函数有epoll_create(), epoll_ctl(), epoll_wait()。其中epoll_create()用于在内核当中创建一个事件表,epoll_ctl()向事件表添加需要监听的文件描述符,epoll_wait()等待事件就绪。
通过epoll_ctl函数添加进来的事件都会被放在红黑树的某个节点内,所以,重复添加是没有用的。当把事件添加进来的时候时候会完成关键的一步,那就是该事件都会与相应的设备(网卡)驱动程序建立回调关系(向内核注册回调函数),当相应的事件发生后(对应的就是socket上有数据可读或者可写),就会调用这个回调函数,该回调函数在内核中被称为:ep_poll_callback,这个回调函数其实就所把这个事件添加到rdllist这个双向链表中。一旦有事件发生,epoll就会将该事件添加到双向链表中。那么当我们调用epoll_wait时,epoll_wait只需要检查rdlist双向链表中是否有存在注册的事件,效率非常可观。当然将rdllink这个双向链表从内核空间拷贝到用户空间是不可避免的。
LT(Level Trigger)与ET(Edge Trigger)工作模式
工作在LT模式下的epoll相当于是高效的poll,LT模式下,epoll_wait检测到有事件发生并通知应用程序的时候,应用程序可以不立即处理这个就绪实践,但是下一次调用epoll_wait的时候,还会告诉应用程序这个事件已经就虚了。知道这个事件被处理了。ET模式下,epoll_wait检测到就绪事件之后必须立即处理就绪事件,如果不处理,之后再次调用不会再通知(一直通知和一次通知的区别)。
EPOLLONESHOT事件
即便是使用了ET模式,一个socket还是可能被多次触发。如果在处理某个socket的时候,又有新的数据来临,此时可能会触发新的线程进行处理,那么会发生多个线程处理同一个socket的情景。如果希望一个socket始终被一个线程处理,那么可以注册为EPOLLONESHOT事件。
