目录
哈希(Hash)
Hash又称为预映射,是通过散列算法将任意长度的输入变换成固定长度的输出,输出值称为散列值。这种转换是一种压缩映射,也就是散列值的空间通常远小于输入的空间,不同的输入可能得到相同的输出,所以不可能从散列值来确定唯一的输入值。
将输入映射为输出的过程可以称之为hash运算过程,常见的hash函数可以划分为:加法Hash;位运算Hash;乘法Hash;除法Hash;查表Hash;混合Hash;例如常见的MD5,MD4,SHA-1算法等,都是基于一系列的复杂的运算构成的。虽然运算过程复杂,但还是不可避免的会出现hash碰撞的问题。
MD5
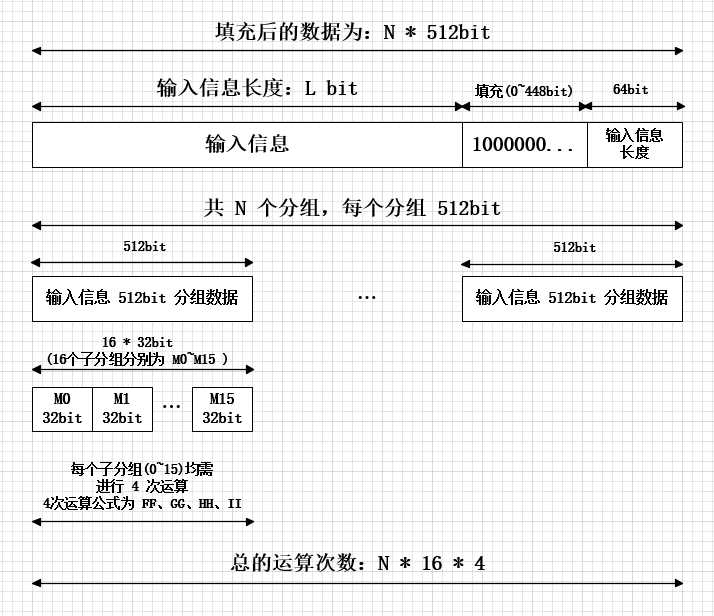
其中MD5运算基本过程为“填充-初始化-分组-混合运算”:
- 填充:将任意长度的输入填充,使得`输入数据 % 512 = 448`,填充部分为`10000....`,剩余64位填充为输入信息的长度。这样得到的输入为512 bit的长度。
- 初始化A,B,C,D四个数据,分别为`A=0x67452301, B=0xefcdab89, c=0x98badcfe, d=0x10325476`,其实初始化输入的时候为`01234567 89abcdef fedc98 76543210`四个4bit的数据,由于计算机是1bit为单位低位开始读取,因此变成上面那种形式。
- 分组:将输入数据分为512 bit一组的数据,其中512 bit又分为16*32 bit的单元。
- 混合计算:每一个32bit的小分组都需要和ABCD四个数字进行混合运算,因此总的运算次数为`N*16*4`,N为512 bit的分组数目。
由于MD5计算的复杂性,理论上来说是不可由输出推断输入的,但是随着近年来计算机算力和密码学理论的发展,MD5已经不再安全,因此RFC 6151提案中已经禁止MD5用作密钥散列消息认证码。
Hash碰撞与解决办法
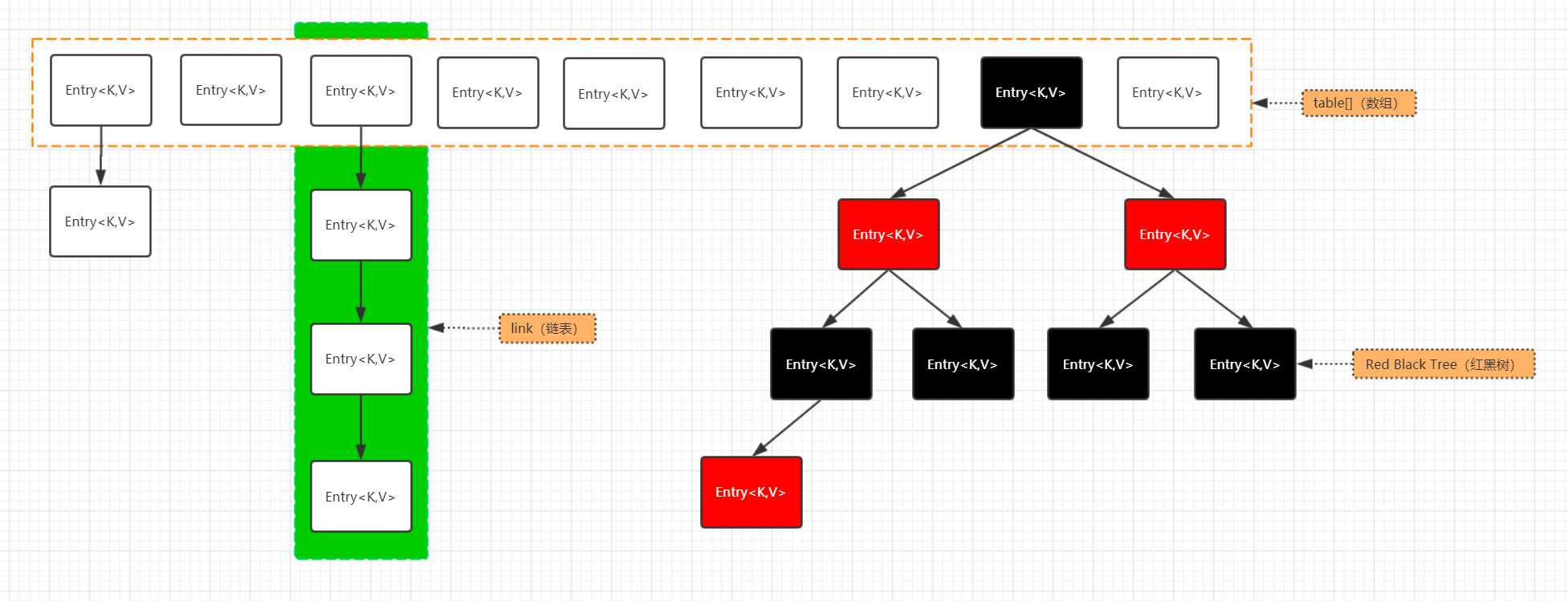
hash函数再强大也只能构建有限空间的映射关系,避免不了在使用hash表储存的时候的碰撞问题。hash的底层实现可以认为是数组和链表以及红黑树组成的,使用红黑树是为了平衡链表O(n)查找的时间复杂度以及数组O(1)的查找时间复杂度,使得平均的查找复杂度更优。但是CPython中的hash表底层实现只是使用了数组实现。这也就决定了两种语言在处理hash冲突上的不一致,Java使用的是分离链接法解决hash冲突,也就是相同的key会以链表或者红黑树的方式组合在一起。CPython中使用的是开放定址法(其中常见的有线性探测、平方探测)来解决,查找的时候一直查找到符合自己的key的值为止。
下面的图片就是java中HashMap的实现示意图,相同键值冲突元素个数的小于8时会采用链表进行储存,超过8的时候采用红黑树进行储存。
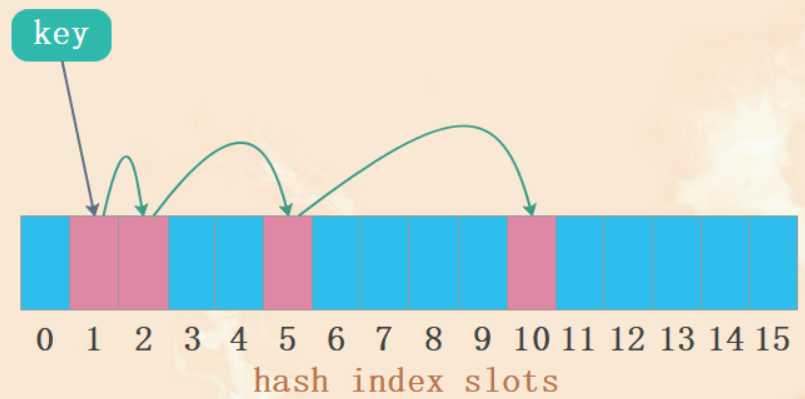
python中的hash表在插入元素的时候,会不断的查看当前hash值的位置有无冲突,如果冲突了那么会一直寻找,直到达到一个空的位置,然后在把<key, value>对储存在数组当中。查找元素的时候,首先找到第一个hash值的槽,如果当前位置的key和待查找的key不同,那么会以约定的方法一直向下寻找,直到找到正确的位置或者key不存在报错。
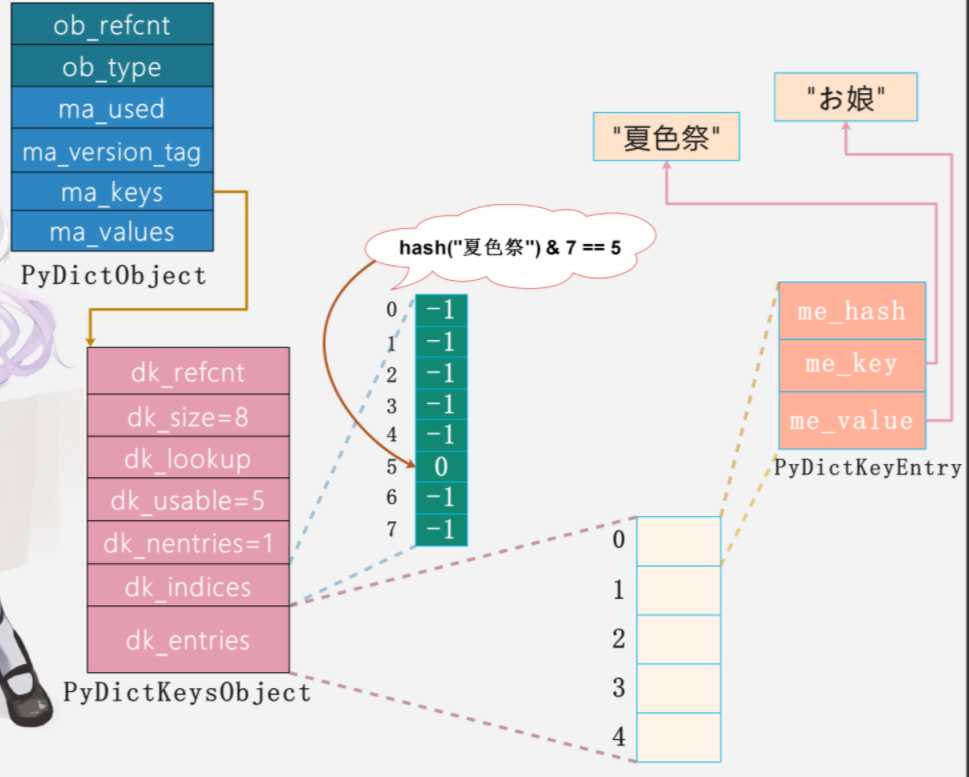
除此之外,CPython中使用了一种非常巧妙的储存方式,不仅可以节省储存空间还可以保证<key, value>按序添加。python中将储存hash索引的数组和储存<key, value>的两个数组分开。下图表示了往空字典插入值的过程,往空字典(python字典初始化容量为8, 不过可用的数量为5个,负载因子为2/3,8*2/3=5,负载因子控制在2/3可以保证可用性和冲突性之间的平衡)中插入键值对的时候,会有以下的步骤:
- 将键值对保存在dk_entries中,由于初始字典是空的,所以会保存在dk_entries数组中索引为0的位置
- 通过哈希函数将键key映射成一个数值,作为在dk_indices的查找索引,假设是5
- 将插入的键值对在数组中的索引0,保存在哈希索引数组中索引为5的槽中
以上只有dk_indices的1/3空间会被浪费,dk_entries的空间会全部被利用。同时由于dk_entries键值对数组是按序添加的,所以在去除的时候也可以按序取出。
同样的在取出某一个key的value的时候会经过以下的步骤:
- 通过哈希函数将键映射成数值,也就是在dk_indices的索引。例如得到的hash值是5。
- 找到dk_indices数组中索引为5的槽,得到其保存的0,这里的0对应键值对数组(dk_entries)的索引
- 找到键值对数组中索引为0的位置,取出value,当然返回结果之前需要先比较key、也就是me_key是否一致, 不一致则重新映射。当然如果该位置为NULL, 那么直接报出KeyError
(图片出处:https://www.cnblogs.com/traditional/p/13503114.html 这篇blog对CPython中的hash分析的非常透彻)
__hash__和__eq__方法
dict,set当中的键值都必须是可哈希对象(hashable),对于可哈希对象而言,必须具备两点特性:
- 哈希值在对象的整个生命周期内不可以改变
- 对象是可以进行比较的,也就是调用==运算的时候需要返回True或者False
python内置的不可变对象-整数、浮点数、字符串、元祖(包含的是不可变的元素,而非类似于z=([1,2,3], 3,0)这种)都可以不作为hash的键值,可变对象-列表,字典都不可作为键值。如果自己实现一个类且没有实现__hash__和__eq__方法的时候,那么会默认继承object中的这两个方法:
def __hash__(self): # 自己实现和默认实现,这个函数都必须返回一个整数值
return hash(id(self))
def __eq__(self, other): # 返回两个对象比较的结果
if isinstance(other, self.__class__):
return hash(id(self))==hash(id(other))
else:
return False
也就意味着,默认情况下除了自己和自己比较,和其他任何对象的比较(==调用__eq__方法和is比较内存地址)都是False。也就说,如果一定要实现一个可哈希对象,那么一定要同时实现__hash__和__eq__方法。如果只是实现__hash__,那么对象只有在和自己比较的时候才相同,其他时候==比较都是False,此时是可哈希对象。如果只实现__eq__那么可能会导致,哈希值比较为True但是==比较为False,此时为不可哈希对象。
元素删除与变容
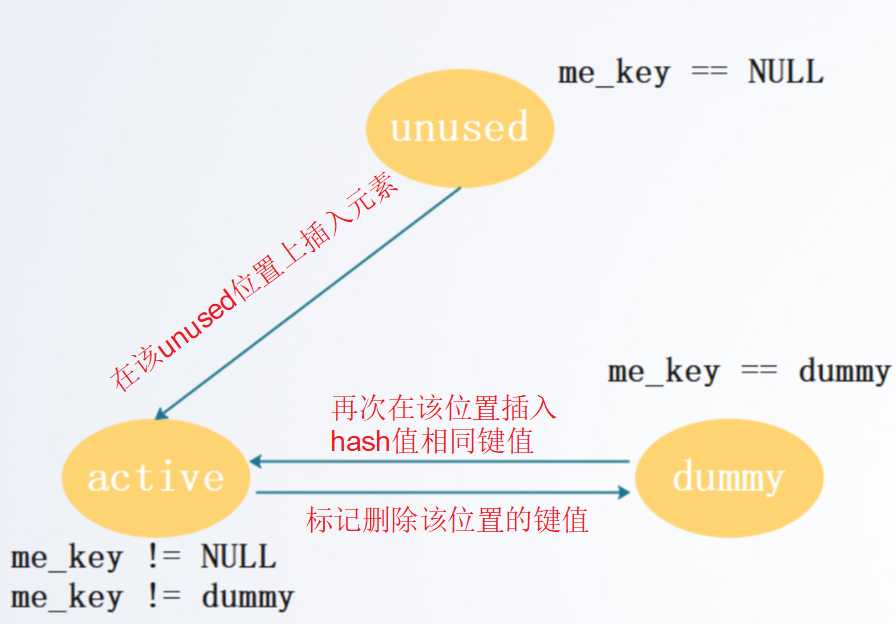
dict和set都是可变的数据结构,也就意味着二者都需要动态的调整储存空间,包括扩容和缩容两个重要操作。实现扩容和缩容的一个很重要的基础就是对dict中的元素进行删除。由于python在解决hash冲突的时候采用的是开放定址当中的二次探测法,因此在对值进行查找的时候可能会存在一条探测链,例如查找key='FIND'的值的时候,可能存在'First'->'Second'->'Example'->'FIND'的探测链。如果在删除的时候直接把其中的'Second'的键值直接删除,在查找的时候会在这个位置无法继续返回一个KeyError的错误,但是实际上'Find'的值是存在的。这种情况称之为探测链断裂。所以在删除的时候,并不是真正意义上的删除而是进行标记性的伪删除。具体而言,每一个PyDictObject对象会被标记为unused态、active态、dummy态中的一个状态。
- unused态表示之前此位置没有储存任何的值,可以储存新的值
- active态表示目前该位置存在有效的键值
- dummy态表示已经被标记删除,如果探测链到了这个位置会接着往下继续查找。如果查找的key和当前位置相同,那么直接返回KeyError。如果是插入操作,除非插入key的hash值和当前位置相同,否则不会更新当前位置,而是去其他位置进行插入。
他们之间的转换关系可以表示为:
如果哈希表满了,那么就申请新的存储单元,然后将所有的active态的entry都搬过去,而处于dummy态的entry则直接丢弃。之所以可以丢弃,是因为dummy状态的entry存在是为了保证探测链不断裂,但是现在所有的active都拷贝到新的内存当中了,它们会形成一条新的探测链,因此也就不需要这些dummy态的entry了。
- 以'Find'键为例,在之前旧空间中的探测链为'First'(active)->'Second'(dummy)->'Example'(active)->'Find'(active)。
- 假设探测函数为X+i^{2},且'First'的hash值为3,'Second','Example'的hash值为3+1^2=4,3+2^2=7,同时Find的hash值也为3。那么第一次找到index为3的位置,发现储存了'First'(active),接着找到3+1^2=4(dummy),3+2^2=7(active)位置发现都被占用。
- 直到找到3+3^2=12位置是空的,此时把'Find'存进去。
- 此时结社进行了扩容,那么'Second'的键值不会进入新的空间,此时'Find'在3+1^2=4位置可以直接找到储存的位置,也就形成了新的探测链: 'First'->'Find'
至于到底是扩容、缩容、还是容量不变,取决于当前哈希表的entry个数。但是无论怎么样,当新的哈希表创建之后,dummy态的位置便又有新的存储单元可用了。对于扩容而言,每次申请新的空间都要大于已用空间的3倍,新空间创建好之后会把之前的元素搬移过去。
